前两天网站莫名其妙炸了,今天花小半天修一修顺便总结一下之前学的数据库及SQL。
PART1.简介 - Database, DBMS, SQL
1.Database:
- In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data(维基百科)
2.DBMS:
- DBMS,即Database Managerment System数据库管理系统, a software system that enables users to define, create, maintain and control access to the database(维基百科)
- DBMS主要分为两类
- 关系数据库(Relational model): 可以理解为一种“表”的数据结构,使用SQL查询。典型例子有MySQL,SQLite,Microsoft SQL Server
- 非关系数据库(NoSQL: 一般使用key-value存储数据/图片/文档。使用例子有redis,MongoDB…
本文主讲Relational model
3.数据库结构:
数据库架构大致分为三层:内层、概念层以及外层.
- External Level and Schema: Defines the user’s view of database. 站在用户交互视角
- Conceptual Level and Schema: Defines what data is stored & raletion between data(当作是DB管理员)
- Internal Level and Schema: Define how data is stored.
4.SQL
- SQL-Structured Query Language结构化查询语句,一种特定目的的程序语言,用于管理关系数据库管理系统(RDBMS)
- 主要包括数据的增,删,查,改,相关语法将在后文介绍
PART2.Relational Model结构及相关该概念
2.1.表的一些描述术语
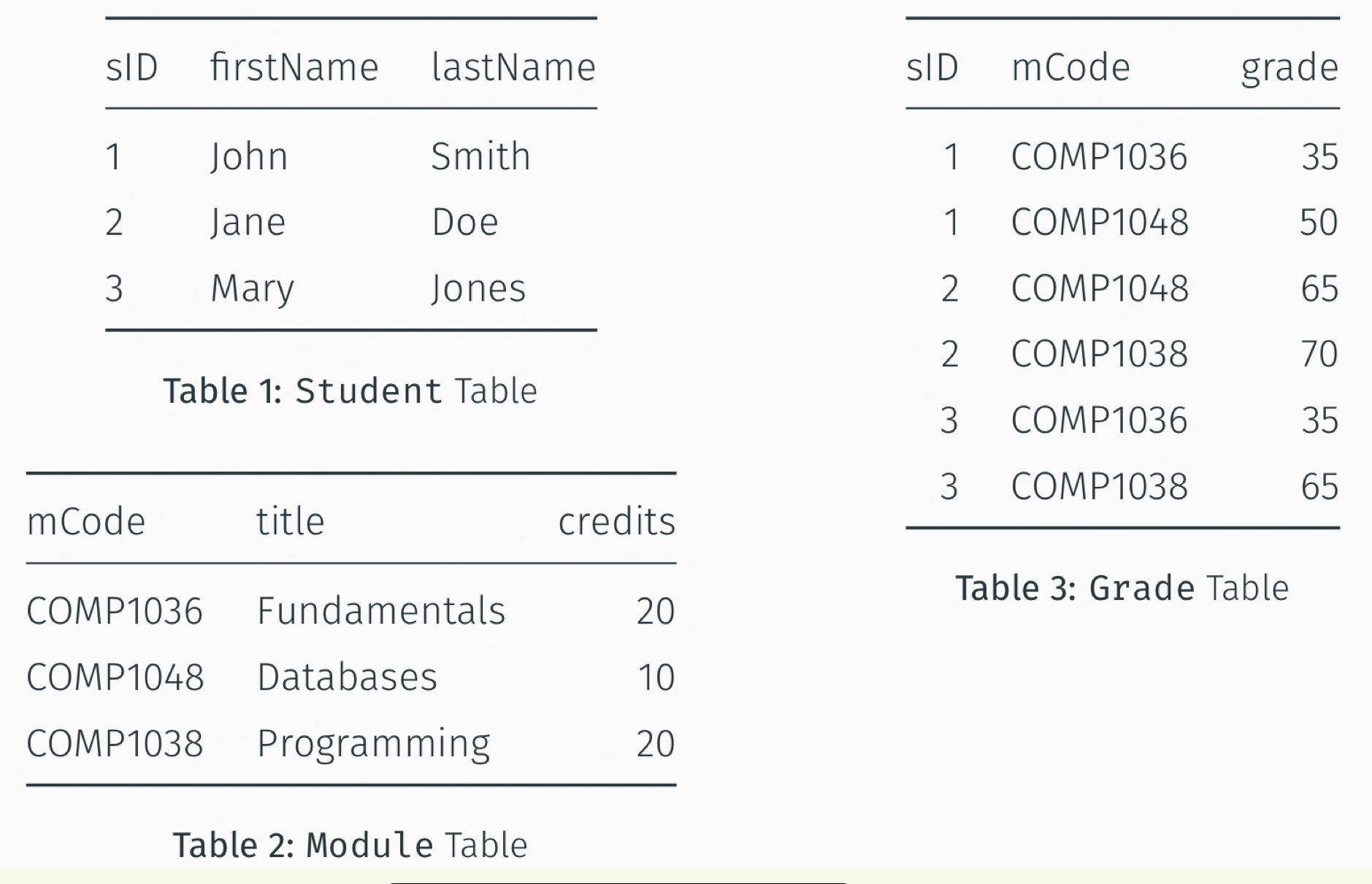
| ID | Name | Salary | Department |
|---|---|---|---|
| 20411616 | Ningbo | 50 | Marketing |
| 20413309 | Yushi | 70 | Human resource |
| 20417813 | Zhihan | 100 | NULL |
Schema: 即heading,表的各类抬头,如上表为{name, id, salary, Department}Tuples: 即row,每张表(mathematical relation)即为a set of tuplesAttributes: 即colum,一列,如{salary,50,70,100}domain: 可以理解为每列的数据种类,如Salary这一column的domain为Integer numDegree of a relation:每一行(tuple)有多长,如上表D为4Cardinality of a relation: 反应本表一共有多少行(tuples),如上表C为3Candidate key:一个单一的域(field)或者组合域,使得其在表里的每条数据都唯一Primary key:如果Candidate key满足独一(unique)且最小(minimal),则该key为peimary key。如上表的PK为{ID},而{name}不唯一,{id,name}不满足最小。Foreign Key:外键,用于连接两个表的数据NULL: 一段损失/未知的数据,不代表为0,含NULL的attribute不可做/组为primary keyReferential Integrity引用完整性: 用于处理当A表引用B表,并且其中一放数据发生改变时另一方该如何改变的选择策略,大致有以下方案:RESTRICT: 保持二表不变,不允许用户改动CASCADE: A/B表跟着改变SET NULL: 让变化的reference value变为NULL
2.2.Relational algebra expression基础运算
主要分为两类,在此只作简单介绍:
Unary Operators一元计算:Selection: 筛选tuples,eg.选出上表中薪水大于70元的学生数据Projection: 筛选Attributes,eg.挑出上表所有学生的薪水
Set Operstors合运算:Union: A∨B -> {A有的+B有的}Set Difference: A-B -> {A有但B没有的}Intersection: A∧B -> {A与B之交集,二者都有的}Cartesian Product卡迪尔积: {a,b}×{c,e} -> {(a,c),(a,e),(b,c),(b,e)}Natural Join: 和Cartesian Product类似,但只保留有关联/相同数据的Tuples,类似的还有Left join/right join。
PART3.SQL及其查询语法
3.1.创表
本文统一使用win10下的sqlite
- 首先我们在sqlite文件夹下创建一个
example.sql文件,先开启外键选项,再输入删除语句防止重复制表。1
2
3
4PRAGMA foreign_keys = ON;
DROP TABLE IF EXISTS Student;
DROP TABLE IF EXISTS Module;
Drop TABLE IF EXISTS Grade; - 接着开始正式制表,sql的指令不分大小写,但一般默认大写。小指令以逗号
,间隔,大指令用封号;分隔。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22CREATE TABLE Student(
sID INTEGER PRIMARY KEY,
firstName TEXT NOT NULL,
lastName TEXT NOT NULL
);
CREATE TABLE Module(
mCode CHAR(8) PRIMARY KEY,
title TEXT NOT NULL,
credits INTEGER NOT NULL
);
CREATE TABLE Grade(
sID INTEGER NOT NULL,
mCode CHAR(8) NOT NULL,
grade INTEGER NOT NULL,
PRIMARY KEY (sID, mCode),
FOREIGN KEY (sID)
REFERENCES Student(sID),
FOREIGN KEY (mCode)
REFERENCES Module(mCode)
);注意其中内键和外键的声明
- 向表格中插入数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17INSERT INTO Student(sID, firstName, lastName)
VALUES (1, 'John', 'Smith'),
(2, 'Jane', 'Doe'),
(3, 'Mary', 'Jones');
INSERT INTO Module(mCode, title, credits)
VALUES ('COMP1036', 'Fundamentals', 20),
('COMP1048', 'Databases', 10),
('COMP1038', 'Programming', 20);
INSERT INTO Grade(sID, mCode, grade)
VALUES (1, 'COMP1036', 35),
(1, 'COMP1048', 50),
(2, 'COMP1048', 65),
(2, 'COMP1038', 70),
(3, 'COMP1036', 35),
(3, 'COMP1038', 65);含有外键(如Grade)的需最后加数据,都则会报错
- 一切写好后,在同文件夹下创建一份
xxx.db文件,它将存储整个数据库的数据。 - 进入sqlite命令窗口,先输入
.open xxx.db打开db文件,再输入.read exmaple.sql,这时sqlite会去读取sql文件内的指令,再在.db文件内生成数据库。 - 最后输入
.schema读取.db文件中的所有table,可以尝试用SELECT * FROM Student看到一个表内的所有数据。如果想显示表格抬头,可输入.header on。
3.2.基础查询语句
- 一般查询语句都以
SELECT+FROM形式,最后以分号;结束 - WHERE是我们的筛选条件,里面可以再嵌套多层SELECT…
- 假设我们现在想选出姓为
Smith和Jones的学生,并按照学号降序排列1
2
3
4
5
6
7
8SELECT
sID, firstName --想要的Attribute
FROM
Student --来自哪个表
WHERE
lastName='Smith' OR lastName='Jones' --condition
ORDER BY
sID DESC; --排列顺序,去掉`DESC`即为升序 - 即可得到:
1
2
3sID|firstName
3|Mary
1|John
3.3.重命名表格
- 一般使用
AS来重命名抬头,或者作为数据reference。1
2
3
4
5SELECT
sID AS StudentID, --如果名称带有空格,用[]或者“”扩起
firstName AS FirstName --注意等下筛选出的数据抬头
FROM
Student1
2
3StudentID|FirstName
3|Mary
1|John - 也可通过重命名表格作为数据reference,连接并筛选两表数据:
1
2
3
4
5
6
7
8
9SELECT
s.sID AS StudentID, --告诉sql我们要的是student还是grade里的sID
s.lastName AS lastName,
g.grade AS Grade
FROM
Student AS s,
Grade AS g
WHERE
s.sID = g.sID; --如果没有这个条件,会得到cartise product(cross join)1
2
3
4
5
6
7StudentID|lastName|Grade
1|Smith|35
1|Smith|50
2|Doe|65
2|Doe|70
3|Jones|35
3|Jones|65
3.4.嵌套选择
- 使用WHERE语句进行嵌套,可以嵌多层,语法大致有
WHERE IN()和WHERE EXISTS两种,及其NOT形式1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20--选出成绩在70分以上的学生姓名(姓名和成绩存在两张表)
SELECT
firstName,lastName
FROM
Student
WHERE sID IN( --IN: is used to check if a value is in a set of value
SELECT sID
FROM Grade
WHERE grade >= 70
);
SELECT
firstName,lastName
FROM
Student
WHERE EXISTS( --EXISIT: is used to check if a set of value is not empty
SELECT sID
FROM Grade
WHERE grade >= 70
AND sID = Student.sID
);
3.5.数据计算与统计
有空更
## 3.6.对字符串数据的处理
有空更
4.Normalization范式
有空更